You won't find anything new or unexpected in this piece - it will only confirm some common observations.
I got interested in those network visualisations you see sometimes, and resolved to make one. As a slave to Twitter, and follower of some of this site's regulars, I thought mapping PI Twitter was a project. It's made with R and Gephi.
First thing is to know what I'm looking for. When you ask Twitter for a user's data, you receive, among other stuff, their self-description, which you can parse for words like 'invest' and 'stock'. You can then, if they don't follow too many people, ask for the list of Followers. So beginning a seed list of accounts, I fanned out, looking at the Follows for possible PIs, then the Follows of those people, jumping around a bit to try to sample the whole space evenly. I also rejected accounts with named foreign locations, very quiet accounts, profligate accounts with more than 1000 friends. Using descriptions as a filter must have missed a lot of people - guesses below, how many.
The rate of return fell off very quickly. I quit at 1200 names, long after additional names became hard to find - and the new names were clogged with mis-hits such as robot news accounts, foreigners - the purpose was to get the shape of the local network rather than be exhaustive. The final list of active near-UK human Twitter PIs is 850 people, of whom [platitude #1] 98% are male. I threw a few famous tweeters into the search just to see how PIs relate to the non-PI world.
Here's a graph of the age of the accounts against log(number of Followers). (ie 3 represents 1000). You can see how fast Twitter took off at the start of 2009. Also note the recent saturation-point with few new accounts this year.
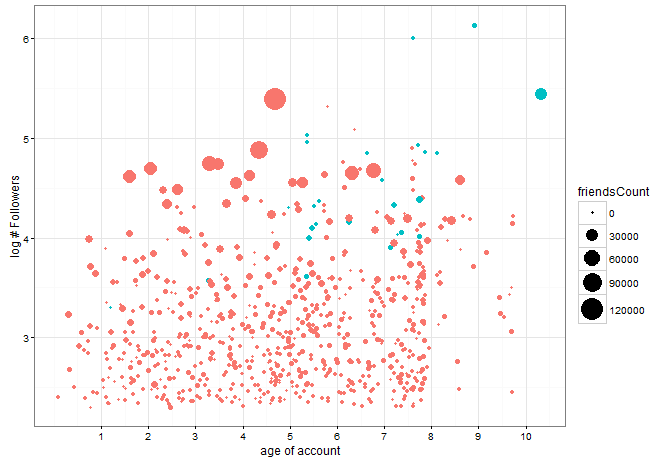
Having found the PIs, I then ask Twitter for all their PI friends. I think this is the thing to ask for (instead of Followers), since it's a deliberate choice, but I'm not sure the result would have been different. Then you cross-reference to see who is in who's list.
And here's the network: the algorithm uses attraction & repulsion to position nodes. A node pulls connected nodes towards itself, while at short range nodes repel each other. Where a tight cluster…



.png)


